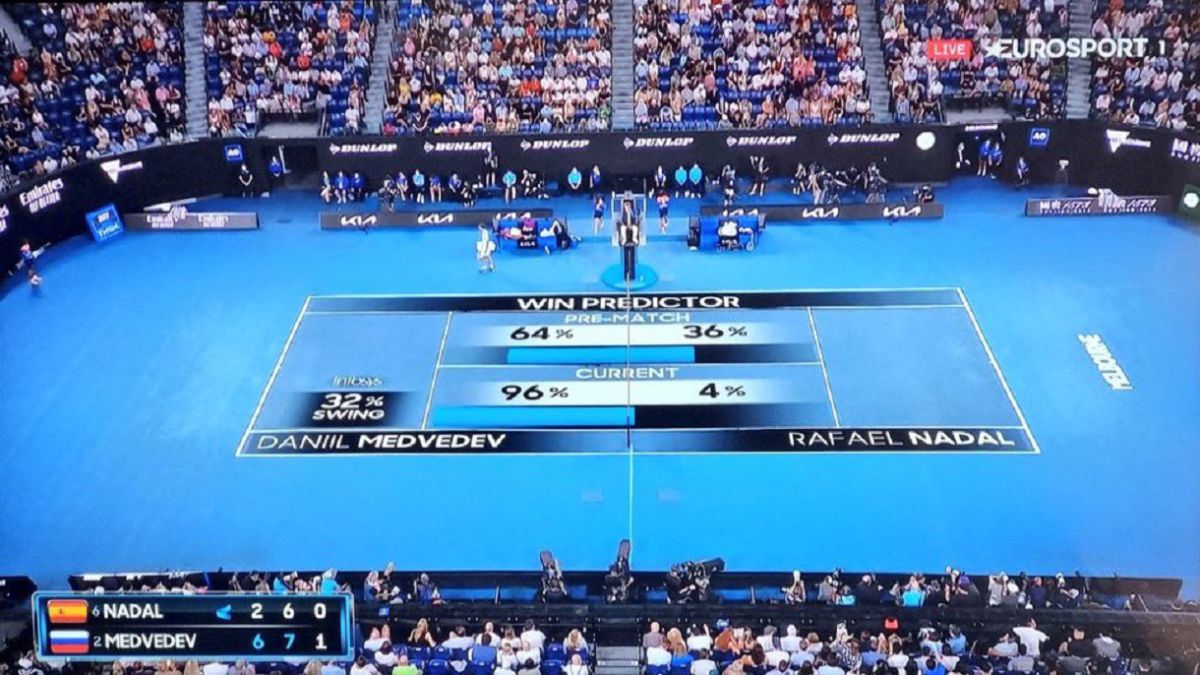
Start of the third set of the Australian Open final. Daniil Medvedev has won two sets and is ahead 0-1 in the third. The television image shows the probability of victory on the track: 96% for the Russian, 4% for the Spanish Rafael Nadal. the rest is history of an epic comeback and the milestone of the ‘Grand Slam’ number 21 for the Spanish. But did Nadal beat the mathematical algorithm? Several experts in data analytics applied to sport analyze the keys for EFE.
That 4% that the ‘win predictor’ of the Australian tournament gave at that time to a comeback from Manacorí -at the start of the match he gave him a 36% chance of winning- has been the subject of jocular comments of all kinds on social networks, all of them carried out a posteriori, when the tenacity of the player with the greatest tournaments in the history of men’s tennis turned an almost lost match into an epic triumph.
However, judging by the experts consulted by EFE, the percentage was justified. In 338 games played by the Spanish tennis player in Grand Slam tournaments, the four main tournaments on the circuit, of 19 situations in which Nadal had started losing 0-2, he had only come back two; and in 13 of them in which he faced a player from the top ten of the ATP circuit he had not prevailed in any. Until Sunday.
“An algorithm does not beat or win. What an algorithm does is based on information, such as Rafa Nadal’s results history, to see how he has fared in that situation. Nadal had never won in that situation. Does that mean that 4% is not going to win a game? No, but that match, in that situation, played 100 times, I would have won it in 4″, Jesus Lagos explains to EFE, partner of ScoutAnalyst, a consultancy that provides data services to Spanish and European football clubs.
In the open era, since 1974, only six tennis players had come back from two sets down in a major tournament final: Bjorn Borg (Roland Garros 1974), Ivan Lendl (Roland Garros 1984), Andre Agassi (Roland Garros 1999), Gaston Gaudio (Roland Garros 2004), Dominic Thiem (US Open 2020) and Novak Djokovic (Roland Garros 2021).
“To be frank, 4% was very generous,” adds Salva Carmona, CEO of the football analytics company Driblab, which works with clubs, player agents and federations.
“From now on, what we all have to think about is whether we are going to have to include other variables in the prediction model, such as fatigue, how long they have run, or if we only take into account the result. There are things that the model does not take into account. And then there is the Nadal factor, who is not just any tennis player, he is a player with 21 Grand Slams, “he adds.
For the data analyst of the sports representation agency YouFirst, Sara Carmona, this case is a sign that data in sports is “a complement” and should not be treated as if it were an absolute truth.
“That 4% gives circumstantial information, a probability that does not have to be fulfilled. Although the normal thing would have been for Nadal not to achieve victory, Mainly because of the dynamics that the game had, but with Nadal we talk about an out of series. Of a competitive animal with a mind as worked as his game, “he notes.
How to squeeze 4%
The key, says Jesús Lagos, is to understand how Nadal managed to squeeze out that 4%. “The grace would be to find out under what patterns that 4% occurs. If it is because you get fewer services and the rival fails more, for example. But that in real time is complicated, and there artificial intelligence adds more value, “he explains.
The Australian Open analyzes its data through a company called Game Insight Group, formed by the Australian tennis federation and the University of Victoria in Melbourne. In addition, in this area it has the sponsorship of the technological consulting firm Infosys, also a sponsor of the ATP circuit, to which it offers its technological platform for data visualization.
This company recently revealed some data that helps to understand how Nadal squeezed that 4% chance. After having an average of 55% accuracy on his first serve in the first two sets, in the third the Spanish champion raised his effectiveness with the service to 82%. He went from 11% accuracy with his forehand in the first set to 35% in the fourth.
An example of working with this data to maximize performance is the team of the Olympic and world badminton champion Carolina Marín, led by her coach Fernando Rivas. “They analyze what he calls the sequences, if a player hits the shuttlecock right, right, left and up, what is the probability of that happening, which allows you to get ahead and make it almost a game of chess,” explains Lagos.
Another element that shines in the case of Rafa Nadal is mental strength. A key that, according to experts, is currently not possible to translate into data incorporated into a probabilistic model. “You can’t get into the model if there isn’t a provider of psychological data, and as far as I know, at least in football there isn’t. In football we usually take into account the idea of playing at home or away, but in tennis players always play outside. The weather, or the quality of the playing field, is not taken into account either,” says Salvador Carmona.
A blow to a flourishing sector
The big data analytics industry applied to sport is a flourishing business. According to the American consulting firm Markets and Markets, these services will grow by 22% per year until adding a market size of more than 5,200 million dollars (4,600 million euros) in 2024.
Rafa Nadal’s achievement compared to the probability associated with the algorithm, can it affect the credibility of the sector in any way? “I think he is going to stay as a joke, but it hurts us as a sector. What has happened with Nadal happens with this type of predictions in football. There are companies that sell to clubs that a player is going to score 25 goals, and they don’t get it right. They generate a lot of noise and a lot of dissatisfaction,” says Jesús Lagos of ScoutAnalyst.
PFor Salvador Carmona, this case will surely be used “as a throwing weapon” against the sector, but it also generates interest that can help the public get a more precise idea of what data analytics is. “There is a lot of information overload, so there will be people who will be curious and will read about it,” says the founder of Driblab.